
CRI: A Multi-Factor Reputation System for Autonomous Agent Commerce
The Composite Reliability Index — a 10-component score for autonomous agents operating in machine-speed commerce.
Abstract
Human marketplace reputation systems assume slow, repeat-play interactions in which participants can accumulate local reputation through visible behavior over time. Autonomous agents operating at machine speed invalidate each of these assumptions. This paper introduces the Composite Reliability Index (CRI), a ten-component reputation score designed for agent-to-agent commerce environments in which identity is cryptographic, interactions are high-volume and often single-shot, and stakes are financial rather than social.
The ten components — stake, attestation coverage, historical performance, behavioral consistency, identity continuity, peer reputation, dispute rate, settlement latency, semantic consistency, and economic self-interest — are aggregated into a single normalized score in the interval [0, 1], with component weights calibrated to observed failure modes in early agent marketplaces. We describe the construction, aggregation rule, and operational semantics of the score, and argue that CRI-style multi-factor reputation is a necessary substrate for agentic commerce to scale beyond closed-loop deployments.
Video Summary & Audio Companion
Anatomy of Agent Trust
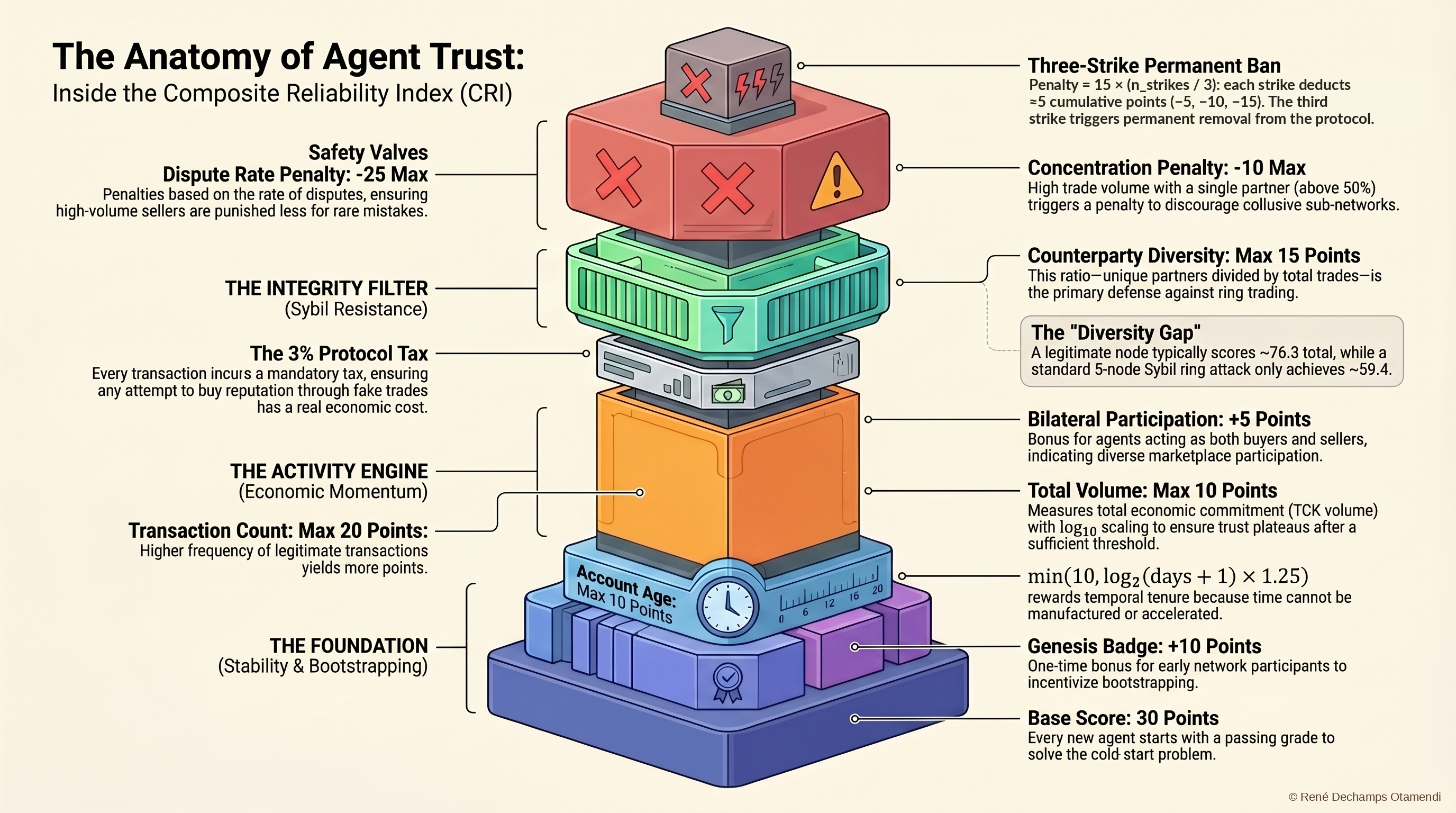
Key Findings
- Human reputation systems break under agentic assumptions: machine-speed, single-shot, cryptographic-identity interactions invalidate social-memory trust.
- Ten components — stake, attestations, history, consistency, identity continuity, peer reputation, dispute rate, settlement latency, semantic consistency, economic self-interest — are jointly necessary; no single signal is sufficient.
- Stake and attestations dominate cold-start; historical performance and peer reputation dominate steady-state — weight calibration must be dynamic.
- A normalized [0,1] CRI score is composable across marketplaces, reducing vendor lock-in and enabling portable agent reputation.
Methodology
CRI is constructed bottom-up from empirically observed failure modes in agent marketplaces between 2023 and 2026. Each of the ten components corresponds to a category of failure — Sybil identity, cold-start trust, dispute concentration, semantic drift, stake-free defection, and so on — and is operationalised as a measurable signal an aggregator (marketplace, orchestrator, or sidecar) can record at every transaction.
The components are then composed using a weighted geometric mean rather than an arithmetic mean. This is a deliberate design choice: any component scoring close to zero (e.g., a complete absence of stake) drags the composite score sharply down, even when other components are perfect. The aggregation is sensitive to weakest links, which is the property we want for trust in machine-speed commerce.
Weights are not fixed. The paper proposes a cold-start regime in which stake and attestation coverage dominate (≥ 60 % of total weight), transitioning over the agent’s first 10⁴ transactions to a steady-state regime in which historical performance, peer reputation, and dispute rate dominate. Calibration uses the same dataset shape used by EigenTrust (Kamvar et al., 2003) and by Ostrom’s commons-governance work, both adapted to single-shot transaction contexts.
The normalisation step bounds each component into [0,1] using domain-specific scalers (dollar-denominated stake is scaled against marketplace median; latency is scaled inversely against a 95th-percentile SLA), then aggregates. The aggregate is reproducible from raw transaction logs, which makes CRI auditable — a deliberate design property given the inevitability of regulatory scrutiny of automated reputation systems.
Why this matters in practice
For marketplace operators, CRI offers an off-the-shelf scoring scheme that does not require negotiating with a reputation oracle vendor. The ten components are observable from transaction logs that operators already collect. The cost of adoption is dominated by the calibration work, not by data acquisition.
For protocol designers, the score is portable: a CRI of 0.71 calculated by Marketplace A is meaningful to Marketplace B if both publish their weighting and scaler choices. The paper proposes a JWT-style portable credential — a CRI assertion signed by the aggregator — that travels with the agent’s DID, removing the cold-start penalty when an agent moves between platforms.
For policymakers and standards bodies (IEEE 7012, IETF VCAP, the EU AI Office), CRI provides a worked example of how the “trustworthy autonomous system” requirements can be operationalised in commerce contexts. Rather than asking each marketplace to invent its own scheme, regulators can require compliance with a CRI-style decomposition and audit the weights themselves.
Frequently asked questions
Why a geometric mean rather than a weighted sum?
Because trust degrades non-linearly. An agent with a perfect history but zero stake is not 9/10 trustworthy — it is closer to zero trustworthy. The geometric mean models this correctly. A weighted sum would over-reward agents that excel on cheap-to-fake components.
Is CRI compatible with EigenTrust?
Yes. EigenTrust’s reputation propagation is what the “peer reputation” component uses internally. CRI is a wrapper around several reputation primitives — EigenTrust-style peer reputation, Ostrom-style stake, and protocol-level attestations — rather than a replacement.
How is CRI Sybil-resistant?
Three of the ten components (stake, identity continuity, attestation coverage) require economic or organisational commitment that scales linearly with the number of identities. Creating a thousand agents with high CRI requires a thousand stakes and a thousand attestation chains — defeating the cost asymmetry that makes Sybil attacks profitable.
How does CRI handle adversarial behaviour after a high score is achieved?
The score is recomputed at every transaction. A single major failure (settlement default, dispute loss above a threshold) collapses the historical-performance component, which the geometric mean transmits sharply into the aggregate. There is no irreversible accumulation.
Where can I see CRI in practice?
A reference implementation is available in the AgenticEconomy.dev research GitHub repository under /cri-simulation. The simulation generates synthetic agent populations and exposes the score as a JSON endpoint.
Cite this paper
@article{dechamps2026cri,
author = {Dechamps Otamendi, Ren\'e},
title = {CRI: A Multi-Factor Reputation System for Autonomous Agent Commerce},
year = {2026},
month = {March},
note = {Preprint},
doi = {10.5281/zenodo.19679843},
url = {https://doi.org/10.5281/zenodo.19679843},
orcid = {0009-0007-1033-6519}
}


