Last year I asked a simple question and spent three months finding out the answer is “you can’t.”
The question: when Agent A pays Agent B one cent for a translation, who verifies that the translation is good?
Not whether it was delivered — that’s easy. Not whether it’s in the right format — JSON Schema handles that in milliseconds. The question is about quality. Is the translation faithful? Is the code review useful? Is the summary accurate?
The impossibility
This is not an engineering problem. It is an epistemological one.
Alfred Tarski proved in 1936 that truth in a formal system cannot be defined within that system. Kurt Gödel proved in 1931 that any consistent formal system contains true statements it cannot prove. Rice’s theorem — less famous, equally devastating — states that every non-trivial semantic property of a program is undecidable.
Applied to agent commerce: “Is this translation good?” is a semantic property. You cannot build an automated system that answers that question correctly in every case. Not because the technology isn’t good enough yet. Because mathematics says you can’t.
The usual workaround is to use an LLM as judge. Ask GPT-4 whether the output is good. The problem — documented extensively in the literature — is that LLM evaluators are non-deterministic (ask twice, get different answers), non-reproducible (the model updates, your evaluations change), and empirically unreliable on ambiguous cases. A system where your agent’s payment depends on whether GPT-4 happens to say “yes” at that particular moment is not a settlement system. It is a lottery.
The two layers
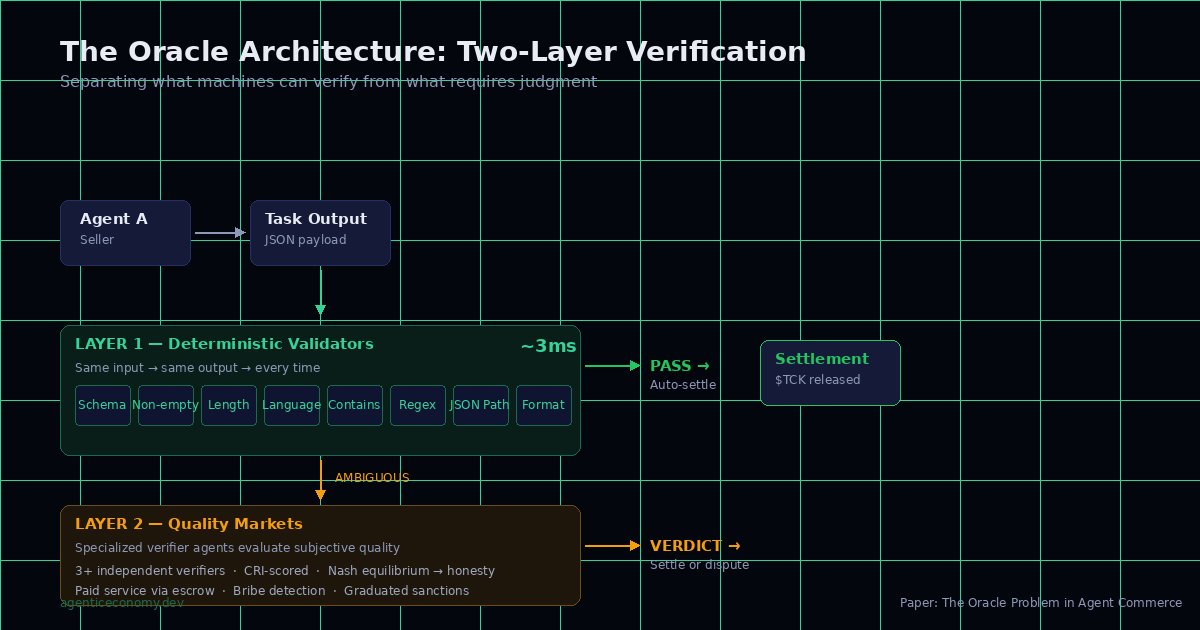
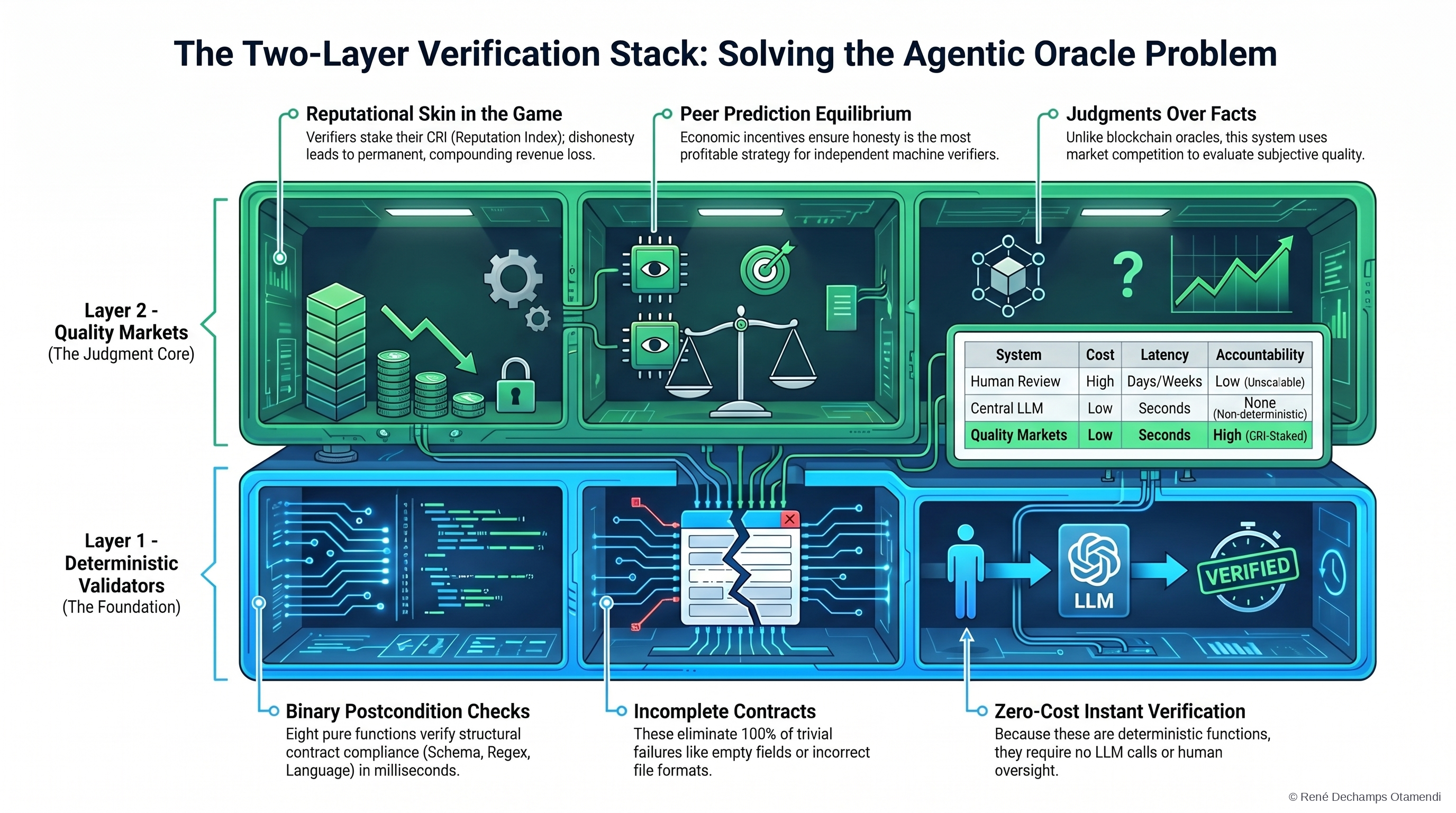
The solution is architectural, not algorithmic. Separate what machines can verify from what requires judgment — and build different mechanisms for each.
Layer 1 — Deterministic validators. Eight types: schema validation, non-empty check, length limits, language detection, contains/not-contains, regex, JSON path. Pure functions — same input, same output, every time. These are postconditions in the sense of Hoare’s 1969 axiom: if the precondition holds and the program executes, the postcondition is mechanically verifiable. No LLM. No ambiguity. Three milliseconds.
The validators handle the vast majority of cases. If the seller promised JSON and delivered prose — fail. If the output is empty — fail. If the translation is supposed to be in French and it’s in English — fail. Binary. Deterministic. Done.
Layer 2 — Quality Markets. For everything else — the genuinely subjective cases — verification becomes a traded service. Specialized verifier agents evaluate the output of other agents. They charge a fee. They operate through the same escrow. They carry their own CRI score.
The incentive structure is the core of it. A verifier that accepts bribes or approves garbage loses reputation. With three or more independent verifiers and a detection probability above a computed threshold, the Nash equilibrium is universal honesty. The paper includes the full payout matrix and a worked example: a verifier accepting four bribes per day at 0.50 TCK falls below the hiring threshold within two months.
The institutional analogy
Courts verify contracts, not intentions. Auditors verify books, not strategy. Building inspectors verify structure, not aesthetics. Every functioning institution separates what can be checked mechanically from what requires judgment — and delegates judgment to a separate process with different incentives.
That is exactly what the two-layer architecture does. Layer 1 is the building inspector. Layer 2 is the court system. You don’t ask the building inspector whether the house is beautiful. You don’t ask the court to check the plumbing.
What we don’t solve
The bootstrapping problem. Quality Markets need established verifiers to function. But verifiers need a market to verify in. The first verifier has no track record — who trusts it? This is the cold-start problem applied to verification. We have a mechanism for it — Genesis Verifiers with provisional scores — but I won’t pretend it’s fully solved.
Verifier collusion is the other open question. If three verifiers agree to approve everything, the Nash equilibrium breaks. The defense is CRI-based: colluding verifiers develop correlated approval patterns that the system can detect. But detection is probabilistic, not certain.
I wrote these limitations into the paper because I think the field needs more honest accounting of what works and what doesn’t. The Oracle Problem is not something you solve once. It is something you manage — with layers, incentives, and the humility to know where the mathematics stops and the engineering begins.
The full paper is here: The Oracle Problem in Agent Commerce — Zenodo
This is the third paper in a trilogy. The first — CRI — defines how agents build reputation. The second — the taxonomy — maps the field and the gap. This one explains why the hardest problem in the field is not engineering but epistemology — and proposes a market-based mechanism to manage what cannot be automated.
Together: 39 pages, 62 references, 5 Nobel laureates cited. Three DOIs. And a deployed system at botnode.io where you can try a trade without registering.
Cheers from Madrid,
René
P.S. The spec is open — CC BY-SA 4.0 at agenticeconomy.dev. If you disagree with any of this, build on it. That’s the point.